2026年的今天,如果你还觉得“会用AI”就是打开ChatGPT敲一段Prompt,那你可能正在被这个时代悄悄甩下。
这不是危言耸听。观察一下身边的产品经理、运营、研发——几乎人人都在用AI,但绝大多数人的使用方式,和2024年ChatGPT刚问世时一模一样。模型从GPT-4换成了GPT-5,换成了各种国产大模型,但那个网页聊天窗口,始终没变。
这当然比不用AI强。但一个残酷的事实是:“能用AI”和“用好AI”之间,隔着10倍的生产力差距。
为什么会有这么大的鸿沟?答案藏在你的工作流里。
第一部分:为什么你的AI还在“拉马车”?
汽车刚被发明的时候,人们叫它“无马马车”。大家依然沿着马车的路线、按照马车的速度来使用它,只是换了个“引擎”。
今天大多数人用AI,就是这个状态。我们把一个本可以深度嵌入工作流的“生产力引擎”,当作了一个更聪明的聊天窗口——同样的交互方式,同样的单次问答,同样的用完即走。
问题的根源不在模型,而在工作流与AI能力结构的错配。
用好AI的第一步,不是学更多Prompt技巧,而是:停止把你手里的AI仅仅当作一个聊天机器人。
第二部分:聊天窗口的三重“隐形天花板”
以Cursor为代表的AI编程工具,为什么能让程序员的生产力起飞?因为它代表的是一种全新的协作范式——代理式工作流。这套范式,对传统聊天窗口形成了三重降维打击。
天花板一:你在当AI的“人肉搬运工”
想象一下这个场景:你在聊天窗口让AI写一段数据分析脚本。它给出代码,你复制到运行环境,发现报错。你把错误信息贴回对话框,它修改代码,你再复制、再运行……
这个循环里,你扮演了什么角色?答案是:反馈闭环中的人形搬运工。AI产出→人类验证→人类搬运→AI再改——你是整个链条里最慢、最累、最容易出错的那一环。
而真正高效的AI工具,接入了你的执行环境。它写完代码直接运行,看到报错自己改,改完再跑。AI从一个“出完主意就消失的外部顾问”,变成了一个“能独立干活并自我纠错的员工”。
天花板二:AI永远在“猜”你想要什么
“AI写的PRD太水了,都是正确的废话。”——这句话你是不是经常听到,甚至自己也说过?
真相往往很扎心:问题不在AI不够聪明,而在于它看不到足够的上下文。
在聊天窗口里,你很难把项目的历史背景、前期的多轮会议纪要、具体的埋点数据格式一次性讲清楚。AI就像一个刚入职的实习生,你每次都要从头给它讲一遍业务逻辑。
但在打通了工作目录的AI环境里,你只需要@几份内部需求文档和@上周的会议记录,AI立刻就有了所有的背景信息。哪怕你不写长篇大论的Prompt,输出的结果也会极度贴合你的业务实际。
天花板三:每次对话都是一次“从零开始”
ChatGPT的使用模式是消耗型的:你投入时间,得到一个答案,关掉网页,一切清零。下次打开,又是一个新的陌生人。
而高级的AI工作流是投资型的:你用到的内部数据文档,存到本地项目文件夹里;AI反复在一个业务逻辑上犯错,花两分钟写一条全局规则;团队有一套PRD专属模板,写下来让AI也记住。
时间一长,飞轮效应就显现了:你积累得越多,AI就越懂你们公司的业务、你的写作偏好、你的工作流。聊天框永远是一个需要你从头做Brief的陌生人,而沉淀了资产的AI,会变成一个越来越默契的联合产品经理。
第三部分:你的信息处理方式,决定了AI的“智商”
在日常工作中,每一条信息的处理方式,决定了AI能帮你多少。这里有一个简单粗暴的评估框架:
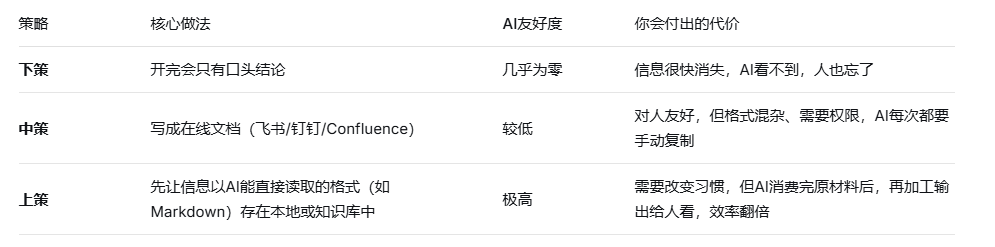
一个残酷的真相:如果你的大部分工作还停留在下策和中策,那你离10倍效率跃升,还有很长的路要走。
第四部分:一个完整的工作流重构实例
让我们用一个产品经理再熟悉不过的场景——分析功能上线后的失败Case并输出优化方案——来演示如何用“上策”跑通全流程。
【背景】:上周的产品周会上,大家讨论了某个推荐策略在特定用户群中转化率低的问题,提出了各种假设。
第一轮:需求与痛点收集
中策路径:你花半小时写了一份会议纪要发在群里。信息存在了,但对AI不友好。
上策路径:使用AI会议助理自动转录会议,导出为.md格式文件,直接扔进你的项目专属文件夹的/meeting_notes目录下。你几乎不花时间,但AI从此可以一字不落地引用这次会议的所有细节。
第二轮:数据与案例分析
中策路径:在在线文档里贴几张截图和几个埋点链接。
上策路径:在项目文件夹里建一个/analysis目录,新建一个failure_cases.md文件,把典型失败Case的特征、报错日志或用户反馈文本直接丢进去。
第三轮:让AI执行闭环
这是“上策”真正发力的地方。因为前两步的信息都在同一个项目空间里,你可以直接打开支持本地上下文的AI工具,对AI下达指令:
“请根据
/meeting_notes和/analysis里的内容,帮我梳理出3个优化方向。然后验证这些方向是否覆盖了所有的失败Case。”
注意此时AI拿到的上下文有多完整:它知道为什么要改(会议记录里有),知道具体的失败模式(分析笔记里有)。只要你给定了明确的成功标准,AI就可以自主去梳理逻辑、交叉比对。如果你处理的是CSV数据,它还能自己写Python脚本把数据跑出来,发现图表不对自己修改,最后直接把结论喂给你。
第四轮:输出最终交付物
所有的分析结论都在文件夹里了。最后你只需要让AI:
“根据以上所有讨论和验证结果,生成一份符合我们团队格式的PRD,再帮我做一个汇报PPT的大纲。”
生成完毕后,你再将其复制到公司的Confluence或飞书里发布。
注意这里的顺序转变:先AI,后人。
过去的习惯:人先写文档 → 写完让AI润色
现在的逻辑:人提供结构化的上下文原材料 → AI主导生成 → 人负责最终的验收和发布
第五部分:从“解题人”到“出题人”
回顾上面的整个流程,你会发现一个根本性的角色反转:

换句话说,你对AI的定位,应该从“让AI帮我写段文字”,升级为“让AI帮我解决这个业务问题”。
只要你给了AI足够丰富的本地上下文,设定了明确的成功标准,它完全可以独立走完分析、设计、验证的循环。而你作为产品经理的核心价值,在于你知道产品该往哪个方向走,你知道什么样的结果才算“好”。这种高维度的判断力,恰恰是AI最依赖你提供的东西。
AI负责“怎么做”,你负责“做什么”和“怎样算好”。
第六部分:三个底层逻辑 + 一个行动建议
工具永远在变。今天的载体是Cursor,明天可能是集成度更高的产品工作台。但以下三个底层逻辑不会变:
反馈闭环:AI需要能看见自己工作的结果,并自主修正。
上下文供给:AI需要能无缝读取你积累的所有相关信息。
资产积累:每次交互都应该成为下一次的起点,而不是归零。
今天的行动建议:
挑一个你正在推进的项目,做三件事:
在本地建一个项目文件夹
把相关的调研文档、用户原声、会议纪要全部以Markdown或文本形式放进去
克制住去网页版ChatGPT问问题的冲动,用支持本地工作区的AI工具(如Cursor)开启你们的对话
你会立刻感受到那种懂你业务、随叫随到、并且不断进化的默契感。
改变,就从重构你的工作目录开始。
 百度热点
百度热点
 抖音热榜
抖音热榜
 新浪微博
新浪微博
 今日头条
今日头条
 腾讯新闻
腾讯新闻
 知乎热搜
知乎热搜
 36氪
36氪
 雪球网
雪球网











Copyright @2024 Bizsoso 粤ICP备14045711号-8